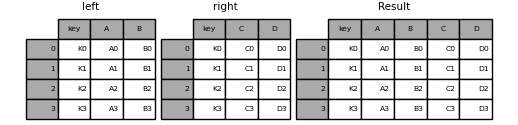
6.1.1 Merge
merge()is used to combine two (or more) dataframes on the basis of values of common columns or indexes as in a RDBMS- If joining columns on columns, the DataFrame indexes will be ignored.
- Otherwise if joining indexes on indexes or indexes on a column or columns, the index will be passed on